ARTIGO ORIGINAL
FAMA, Josué Sá [1]
FAMA, Josué Sá. Inteligência artificial e privacidade: implicações legais e éticas na era digital. Revista Científica Multidisciplinar Núcleo do Conhecimento. Ano. 10, Ed. 01, Vol. 01, pp. 15-39. Janeiro de 2024. ISSN: 2448-0959, Link de acesso: https://www.nucleodoconhecimento.com.br/tecnologia/implicacoes-legais, DOI: 10.32749/nucleodoconhecimento.com.br/tecnologia/implicacoes-legais
RESUMO
Este artigo busca aprofundar os desafios legais e éticos relacionados à interação entre inteligência artificial (IA) e privacidade de dados na atual era digital. Abordaremos questões cruciais, como transparência algorítmica, explicabilidade dos sistemas de IA e discriminação algorítmica, examinando seus impactos na salvaguarda da privacidade individual. Além disso, analisaremos as implicações das regulamentações de proteção de dados, como o Regulamento Geral de Proteção de Dados (GDPR) e a Lei Geral de Proteção de Dados (LGPD), na implementação das tecnologias de IA e na promoção da privacidade e equidade na sociedade digital. Esse estudo visa contribuir para uma compreensão mais abrangente das complexidades envolvidas na utilização da IA em um contexto em que a privacidade dos dados é cada vez mais valorizada e debatida.
Palavras-chave: Inteligência Artificial, Privacidade, GDPR, LGPD, Sociedade Digital.
1. INTRODUÇÃO
A crescente integração da Inteligência Artificial, onde citaremos como IA nas discussões, em vários aspectos da vida humana, incluindo profissional, intelectual, economia e saúde, produz preocupações éticas significativas entre os profissionais de privacidade, as quais podem resultar em processos judiciais. De acordo com Lichtenthaler (2019) a IA engloba o desenvolvimento de sistemas computacionais capazes de realizar tarefas que normalmente requerem inteligência humana, como percepção visual, reconhecimento de fala, tomada de decisões entre outras. Consequentemente, a IA emergiu rapidamente como um campo popular e em avanço dentro da ciência da computação, com o potencial de revolucionar muitos aspectos da existência humana.
Esse avanço levou grandes organizações a acelerarem o desenvolvimento de IA estabelecendo laços cada vez mais estreitos com essa tecnologia em suas atividades e operações. Essa dependência crescente dos sistemas de IA suscitou preocupações éticas que demandam atenção. O desenvolvimento e a implementação de tais sistemas devem ser pautados por princípios éticos, garantindo que sejam empregados para o benefício e aprimoramento da sociedade.
Como enfatizado por Challen et al. (2019), uma das questões éticas significativas em torno da IA é o viés, considerando discriminação algorítmica. Os sistemas de IA podem exibir vieses de várias maneiras, incluindo vieses raciais, de gênero e culturais. Por exemplo, algoritmos de IA usados em processos de contratação podem apresentar vieses de gênero, resultando na sub-representação de mulheres em determinadas funções. Da mesma forma, sistemas de reconhecimento facial podem exibir vieses raciais, levando à identificação incorreta de indivíduos de certos grupos raciais. Preocupações éticas sobre o viés na IA são duplas: primeiro, sistemas de IA tendenciosos podem perpetuar e amplificar vieses sociais e discriminação existentes e, segundo o uso de sistemas de IA tendenciosos pode resultar em tratamento injusto de indivíduos. Por exemplo, sistemas de reconhecimento facial demonstraram ter taxas de erro mais altas para indivíduos com tons de pele mais escuros do que para aqueles com tons de pele mais claros (Krishnapriya, Pooja e Sridevi, 2020).
Conforme afirmado por Jobin et al. (2019), outra consideração ética significativa em torno da IA é a privacidade. Preocupações com a privacidade na IA se referem a preocupações relacionadas à coleta, armazenamento e utilização de informações pessoais pelos sistemas de IA. Os sistemas de IA têm a capacidade de coletar e analisar grandes quantidades de dados pessoais, e se esses dados não forem tratados adequadamente, podem levar a preocupações significativas com a privacidade (Jobin et al., 2019). Os sistemas de IA frequentemente coletam vastas quantidades de dados de indivíduos, que podem ser usados para tomar decisões sobre eles. Isso levanta preocupações sobre como esses dados são coletados, armazenados e usados. Além disso, o uso de IA em sistemas de vigilância pode infringir os direitos de privacidade individuais (Palaiogeorgou et al., 2021). Uma das principais preocupações de privacidade relacionadas à IA é o potencial uso de informações pessoais para fins não intencionais. Por exemplo, as informações pessoais coletadas por um sistema de IA para um fim, como publicidade direcionada, podem ser usadas para outros fins, como roubo de identidade. Além disso, os sistemas de IA podem coletar dados sobre indivíduos sem o seu conhecimento ou consentimento, o que pode levar a violações de privacidade.
Outra preocupação de privacidade relacionada à IA é o potencial de violações de dados (Murdoch, 2021). Se os dados pessoais não forem adequadamente protegidos, podem ser acessados por indivíduos não autorizados, resultando em roubo de identidade e outras formas de fraude. Isso é particularmente preocupante dada a natureza sensível dos dados coletados por muitos sistemas de IA, como dados de saúde e informações financeiras. O uso de sistemas de IA em vigilância também levanta preocupações significativas de privacidade. De acordo com Murdoch (2021), os sistemas de IA estão sendo cada vez mais utilizados para reconhecimento facial e outras formas de identificação biométrica, que podem ser usados para rastrear indivíduos e monitorar seu comportamento sem o seu conhecimento ou consentimento. Isso pode levar a violações significativas de privacidade e liberdades civis.
O uso de sistemas de IA levanta preocupações significativas sobre a responsabilidade. Questões de responsabilidade na IA referem-se à responsabilidade e obrigação associadas às ações e decisões tomadas pelos sistemas de IA (Tóth et al., 2022). Um dos principais desafios relacionados à responsabilidade na IA é a falta de transparência no processo de tomada de decisão. Os sistemas de IA muitas vezes dependem de algoritmos complexos e modelos de aprendizado de máquina que podem ser difíceis de entender, mesmo pelos desenvolvedores que os criaram. Além disso, à medida que os sistemas de IA se tornam mais autônomos, torna-se cada vez mais difícil responsabilizar indivíduos ou organizações por suas ações. Os sistemas de IA estão sendo cada vez mais usados para tomar decisões que têm impactos significativos nos indivíduos e na sociedade como um todo, como decisões relacionadas à saúde, finanças e aplicação da lei. No entanto, a natureza complexa e opaca dos sistemas de IA pode dificultar a identificação de quem é responsável pelas ações e decisões tomadas por esses sistemas. Os sistemas de IA podem ter impactos imprevistos nos indivíduos e na sociedade e, se esses impactos forem negativos, pode ser difícil identificar quem é responsável pelos danos causados.
De acordo com Bertino, Kundu e Sura (2019), a transparência algorítmica é outra consideração ética crítica na IA. A transparência na IA refere-se à capacidade de um sistema de IA explicar suas decisões e ações. Isso é importante porque permite que as pessoas entendam por que o sistema tomou uma determinada decisão e avaliem a justiça e a confiabilidade do sistema. No entanto, um dos maiores problemas de transparência na IA é a falta de clareza nos algoritmos usados para tomar decisões, o que denominamos explicabilidade dos sistemas de IA. Muitos algoritmos de aprendizado de máquina são complexos e difíceis de entender, mesmo para especialistas na área. Isso pode dificultar a determinação de como o sistema toma decisões, levando a preocupações sobre preconceitos e discriminação.
Outra questão de transparência na IA é a falta de transparência nos dados usados para treinar o sistema (Schmidt, Biessmann, & Teubner, 2020). Os algoritmos de aprendizado de máquina dependem de grandes quantidades de dados para aprender como tomar decisões. No entanto, se os dados forem tendenciosos ou incompletos, isso pode resultar em um sistema de IA tendencioso e impreciso. Se um sistema de IA tomar uma decisão que prejudique alguém, é importante poder determinar quem é o responsável por essa decisão. No entanto, em muitos casos, pode ser difícil rastrear o processo de tomada de decisão até ao indivíduo ou equipe que desenvolveu o sistema. Os sistemas de IA podem ser complexos e opacos, tornando difícil compreender como tomam decisões. Isso levanta preocupações sobre justiça e responsabilidade, uma vez que os indivíduos podem não compreender os fatores que influenciam as decisões tomadas pelos sistemas de IA.
2. DESENVOLVIMENTO
2.1 O CONCEITO DE PRIVACIDADE NA ERA DIGITAL
A privacidade, antes um conceito relativamente simples, tornou-se uma questão complexa na era digital, onde a coleta e o compartilhamento de dados são cada vez mais frequentes. A proliferação de dispositivos conectados, aplicativos e plataformas online gera um fluxo constante de informações pessoais, tornando a proteção da privacidade um desafio crescente.
Conforme Chen (2020), na vida, todos guardam um segredo pessoal que desejam manter oculto dos outros, e esse segredo não afeta os interesses legítimos de terceiros. Legalmente, esse segredo é referido como privacidade, englobando aspectos como vida privada, diário, álbum de fotos, hábitos de vida, comunicações privadas, entre outros. É um direito fundamental preservar tais segredos longe do conhecimento alheio. Este direito é conhecido como direito à privacidade.
Na era da inteligência artificial, os usuários se veem cada vez mais vulneráveis ao vazamento de dados pessoais. Os softwares de IA atuais têm a capacidade de integrar informações dispersas de um usuário em diferentes plataformas online, completando assim um retrato detalhado dele.
Logo, na sociedade online, a privacidade pessoal tornou-se uma mercadoria negociável. Na chamada dark web, a privacidade pessoal é comprada e vendida. Portanto, tanto do ponto de vista jurídico quanto tecnológico, a proteção da privacidade pessoal tornou-se uma questão de extrema urgência.
2.2 IMPACTO DA IA NA PRIVACIDADE INDIVIDUAL
Conforme Chen (2020) destaca, mesmo que um usuário nunca tenha compartilhado informações pessoais completas com qualquer plataforma online ou instituição, a inteligência artificial ainda é capaz de integrar totalmente a privacidade pessoal de cada usuário da internet em dados comerciais. Isso é possível através do uso de tecnologias como a mineração de dados não padronizados e a construção de perfis de comportamento de rede, utilizado bastante na área do marketing para concentração de leads para transformação em perfis de clientes potenciais. Chen (2020) ainda ressalta que essas técnicas envolvem quatro etapas distintas: rastreamento de informações, integração de dados, análise de recursos e construção do perfil do usuário, também chamado mineração de uso da Web conforme Cooley, Mobasher e Srivastava (1997). Os dados de privacidade pessoal integrados pela IA podem ser explorados em várias campanhas publicitárias e até mesmo vendidos a infratores para fins ilegais.
Veja o quadro desenhado por Chen (2020):
Figura 1. Mineração de Fragmentos de Dados Pessoais sob Condições de Tecnologia de IA
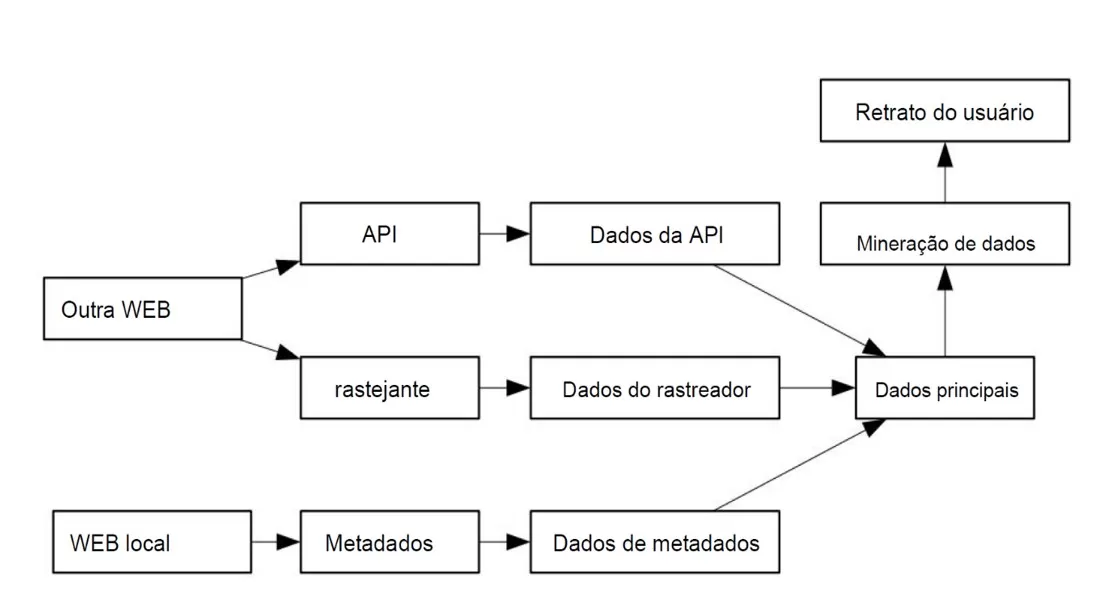
A figura desenhada por Chen (2020) explica que o Rastreador de Informações é uma tecnologia projetada para coletar e filtrar dados de hipertexto retornados ao navegador por meio de solicitações HTTP ou HTTPS, acessando legalmente URLs ou XML e extrair informações úteis desses dados após remover declarações identificadoras. Embora todas as tecnologias empregadas pelo Rastreador de Informações sejam legais, seu objetivo final muitas vezes não é. Por isso, a maioria dos sites implementa funções de rastreamento de dados correspondentes, mas isso não elimina completamente os potenciais danos causados pelo Rastreador de Informações.
O estudo de Chen (2020) revela que os dados do usuário por meio da análise de recursos expuseram quase toda a privacidade do usuário, dados pessoais como: as informações de contato do usuário, status de ativos, dados de crédito, dados relevantes de casamento e familiares, todos os dados mencionados expostos.
Os impactos na exposição dos dados pessoais nessas condições, ao alcançarem o nível da intimidade do indivíduo, tendem a ser irreversíveis. À medida que a IA avança, impulsionada pela busca desenfreada por lucro por parte das organizações, torna-se cada vez mais difícil evitar que os sites compartilhem dados pessoais em conformidade com as regulamentações.
2.3 MINERAÇÃO DE FRAGMENTOS DE DADOS PESSOAIS
A IA pode integrar informações dispersas de um usuário em diferentes plataformas online, construindo um perfil detalhado do indivíduo. Esse processo, conhecido como mineração de dados não padronizados, pode gerar um retrato completo do usuário mesmo que ele não tenha compartilhado informações pessoais completas. A figura 1 ilustra esse processo, mostrando como a IA pode coletar e integrar dados de diferentes fontes para criar um perfil completo do usuário.
2.4 USO DE DADOS PESSOAIS POR SISTEMAS DE IA
A caracterização da atualidade como a Era dos Dados é cada vez mais evidente. Se traçarmos uma linha histórica, veremos que antes de 1980, os dados ficavam quase exclusivamente em datacenters, com foco apenas nos negócios, e a computação era centralizada. Entre 1980 e 2000, houve uma transição significativa, com os dados e a computação passando a ser distribuídos, enquanto os centros de dados assumiam um papel crucial no gerenciamento de dados, e ocorria uma expansão notável na área do entretenimento. De 2000 até os dias de hoje, presenciamos uma evolução ainda maior, com os centros de dados migrando para o armazenamento em nuvem, mantendo-se a computação distribuída e adicionando-se às tendências as redes sociais. Essa é a situação do mundo guiado por dados.
A democratização da IA revolucionou a forma como clientes e empresas se relacionam. A IA opera com base em dados e, portanto, depende de técnicas avançadas de ciência de dados. Conceitualmente, a ciência de dados é uma disciplina que visa desenvolver ferramentas e métodos para analisar grandes volumes de dados e extrair informações valiosas a partir deles. Algumas das técnicas mais populares na ciência de dados incluem Reconhecimento de Padrões (PR), Aprendizado de Máquina (ML), Big Data Analytics (BDA), entre outras. Dentre essas técnicas, o ML é uma das mais amplamente utilizadas para impulsionar a IA.
Atualmente, geramos uma quantidade exorbitante de informações: estima-se que até 2025, o mundo terá mais de 180 zettabytes de dados (um zettabyte possui 21 zeros e equivale a um trilhão de gigabytes), conforme projeções de Taylor (2023).
Além disso, com o progresso tecnológico, adquirimos a capacidade de criar métodos mais eficientes e econômicos para armazenar e processar esses dados, transformando-os em aplicações cada vez mais poderosas que revolucionam nossa percepção do mundo.
O êxito das tecnologias baseadas em ML é, em grande parte, atribuível à disponibilidade quase ilimitada de dados.
Em um contexto tradicional de ML, para extrair conhecimento, os dados devem ser enviados a um servidor centralizado, onde ocorre todo o processamento necessário. Em outras palavras, todas as informações, inclusive dados pessoais, são enviadas e armazenadas em um único local. E esse local raramente é onde os dados foram gerados, o que significa que informações cruciais estão sendo transferidas de um ponto a outro continuamente.
Figura 2. Fluxo de informações pela rede em quatro arquiteturas de ML. As linhas sólidas representam o fluxo de dados de treinamento, as linhas tracejadas representam o fluxo dos parâmetros do modelo. Artigo: Sistemas de recomendação sob regulamentos europeus de IA
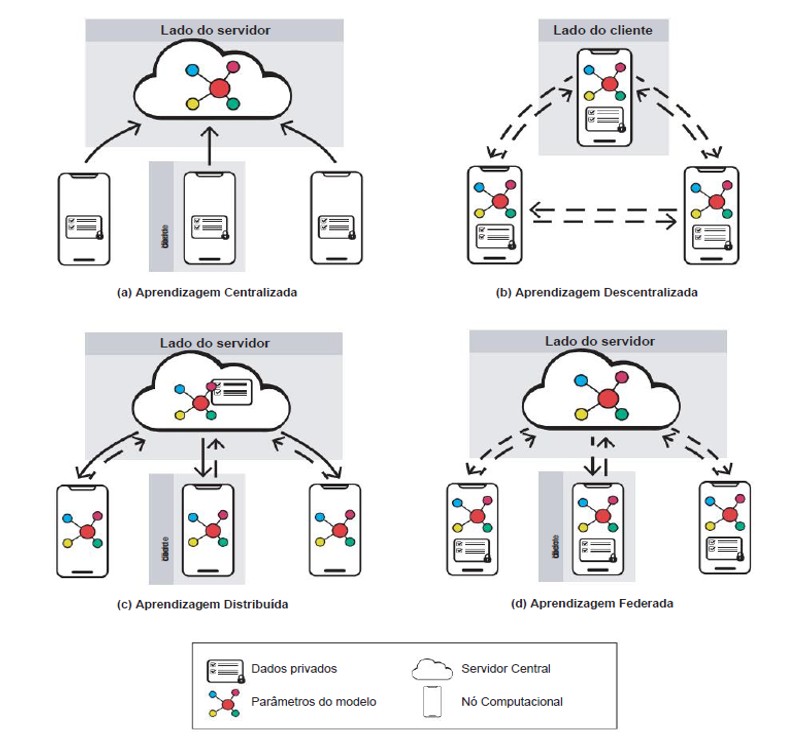
Com base na ilustração fornecida no artigo mencionado, entre várias arquiteturas de aprendizado de máquina, destacaremos algumas abordagens, tais como a aprendizagem centralizada, descentralizada, distribuída e federada. Estas abordagens representam diferentes paradigmas de implementação da inteligência artificial, cada uma com suas características e aplicações específicas. Ao compreendermos essas nuances, podemos avaliar como cada uma delas contribui para a eficiência e a ética no uso da IA em diversos contextos.
A aprendizagem centralizada é o paradigma tradicional, onde todos os dados são reunidos em um único local para treinar um modelo de aprendizado de máquina. Isso geralmente ocorre em data centers ou servidores em nuvem, onde os dados são processados e analisados em massa. Embora seja eficaz em termos de desempenho e eficiência computacional, a aprendizagem centralizada apresenta desafios significativos em termos de privacidade e segurança dos dados, uma vez que todos os dados precisam ser compartilhados com uma entidade central.
Por outro lado, a aprendizagem descentralizada distribui o processo de treinamento para vários dispositivos ou locais, onde os modelos são treinados localmente nos dados disponíveis em cada dispositivo. Essa abordagem é mais adequada para cenários em que os dados são sensíveis ou restritos e não podem ser compartilhados centralmente. No entanto, a descentralização pode resultar em modelos de qualidade inferior devido à falta de dados representativos ou à heterogeneidade dos dados em diferentes dispositivos.
A aprendizagem distribuída é uma extensão da aprendizagem descentralizada, onde o processo de treinamento é distribuído entre vários dispositivos ou locais, mas os modelos são agregados em um servidor central para obter um modelo global. Isso permite combinar o conhecimento de diferentes fontes de dados e melhorar a precisão do modelo final. No entanto, ainda existem desafios em termos de comunicação e coordenação entre os dispositivos durante o processo de treinamento distribuído.
Por fim, a aprendizagem federada é uma abordagem emergente que combina os benefícios da descentralização com a capacidade de criar modelos globais de alta qualidade. Nesse paradigma, os modelos são treinados localmente em cada dispositivo, e apenas os pesos do modelo são compartilhados e agregados em um servidor central. Isso preserva a privacidade dos dados enquanto permite a criação de modelos globais robustos. No entanto, a aprendizagem federada ainda está em estágio inicial de desenvolvimento e requer mais pesquisa para resolver desafios técnicos e garantir a segurança e privacidade dos dados.
Portanto, essas diversas arquiteturas oferecem uma ampla gama de soluções para os desafios decorrentes da integração entre IA e privacidade de dados na sociedade digital contemporânea. Uma compreensão aprofundada de suas características e aplicações é crucial para a implementação ética e eficiente de sistemas de IA, especialmente em um cenário onde a proteção dos dados pessoais é cada vez mais valorizada e debatida. É imperativo abordar os riscos de violação da privacidade, ressaltando a importância de estratégias adequadas de proteção de dados em cada arquitetura de IA. O aprendizado federado voltado para a preservação da privacidade busca equipar os sistemas de ML com medidas defensivas para salvaguardar a privacidade dos usuários e a segurança dos dados, diferenciando-se do ML seguro, cujo foco está na proteção da integridade e disponibilidade do sistema de ML contra-ataques maliciosos.
2.5 ARQUITETURAS DE APRENDIZADO DE MÁQUINA E PRIVACIDADE
Existem diferentes arquiteturas de aprendizado de máquina (ML) que influenciam a forma como os dados são tratados e a privacidade dos usuários. A figura 2 ilustra algumas dessas arquiteturas, como aprendizagem centralizada, descentralizada, distribuída e federada, mostrando como o fluxo de informações varia em cada caso.
2.6 RISCO DE VIOLAÇÃO DE PRIVACIDADE
Conforme apontado por Ravi e Ignatius (2023), a Inteligência Artificial (IA) prolifera novos riscos à privacidade. Embora a pesquisa não detalhe a natureza desses riscos, é possível inferir que eles decorrem da forma como os sistemas de IA coletam, processam e utilizam dados pessoais.
A amplitude e a complexidade dos dados utilizados por sistemas de IA, muitas vezes combinando informações de diferentes fontes, aumentam a probabilidade de violações de privacidade. Vejamos alguns dos principais riscos de violação de privacidade relacionados à IA:
- Coleta massiva de dados: Os sistemas de IA frequentemente exigem a coleta de grandes volumes de dados, incluindo informações pessoais sensíveis. Essa coleta indiscriminada pode levar à exposição de dados confidenciais, como informações médicas, financeiras ou de localização.
- Processamento de dados sem consentimento: A falta de transparência sobre como os dados são processados e utilizados pelos sistemas de IA pode resultar em violações de privacidade. O consentimento do usuário para a coleta e uso de dados nem sempre é claro ou adequadamente informado, especialmente no que diz respeito ao processamento complexo realizado por algoritmos.
- Monitoramento constante: A IA permite o monitoramento constante de indivíduos através de dispositivos conectados, câmeras de vigilância e coleta de dados online. Essa vigilância intrusiva levanta preocupações sobre a perda de privacidade e a possibilidade de abuso por parte de governos e empresas.
- Perfilhamento e segmentação: Os sistemas de IA podem criar perfis detalhados de indivíduos com base em seus dados, incluindo informações sobre seus hábitos, preferências e comportamento. Essas informações podem ser usadas para segmentação de anúncios, manipulação de informações e discriminação, violando o direito à privacidade e autonomia individual.
- Ataques cibernéticos: Os sistemas de IA, por sua natureza complexa, podem ser vulneráveis a ataques cibernéticos, que podem resultar na exposição de dados pessoais sensíveis e na violação da privacidade de indivíduos e organizações.
- Falta de regulamentação específica: As leis de proteção de dados existentes podem ser insuficientes para lidar com as nuances da IA e as formas complexas de coleta e uso de dados. A necessidade de leis e regulamentações específicas para a IA é crucial para garantir a privacidade e a proteção dos dados
2.7 REGULAMENTAÇÕES DE PROTEÇÃO DADOS E IA
Em 13 de março de 2024, o Parlamento Europeu deu um passo importante para regular a inteligência artificial (IA), que entrou em vigor em agosto de 2024. Essa lei inovadora, estabelece um conjunto de regras para o desenvolvimento e uso da IA na Europa.
A Lei de IA tem como objetivo principal garantir que a IA seja usada de forma segura, ética e responsável. Ela visa proteger os direitos e liberdades fundamentais dos cidadãos, promover a inovação e garantir que a IA contribua para uma sociedade justa e próspera. Alguns dos principais pontos da Lei de IA incluem:
a) Proibição de sistemas de IA que causem danos à saúde, segurança ou direitos fundamentais das pessoas. Isso inclui sistemas de reconhecimento facial em tempo real e sistemas de pontuação social.
b) Exigências rigorosas de transparência e explicabilidade para os sistemas de IA. As empresas precisarão ser capazes de explicar como seus sistemas de IA funcionam e quais dados eles usam.
c) Obrigação de que os sistemas de IA sejam submetidos a avaliações de conformidade por parte de autoridades independentes. Isso visa garantir que os sistemas atendam aos requisitos da lei.
d) Estabelecimento de um sistema de supervisão e aplicação da lei robusto. A Comissão Europeia será responsável por supervisionar a implementação da lei e por aplicar sanções às empresas que não a cumprirem.
No Brasil, o Projeto de Lei nº 2338/2023, apresentado pelo Senado Federal, visa regulamentar o uso da Inteligência Artificial (IA) no Brasil, com foco em uma abordagem baseada em riscos e direitos. O PL busca harmonizar a proteção de liberdades fundamentais com a inovação e a criação de novas cadeias de valor. Algumas considerações e pontos chaves do projeto de lei:
a) Classificação de risco: O PL define categorias de risco para sistemas de IA, com foco especial em sistemas de alto risco, que podem afetar significativamente os direitos e interesses das pessoas.
b) Proteção de dados: O PL reconhece a importância da proteção de dados pessoais e estabelece uma forte interação com a Lei Geral de Proteção de Dados (LGPD), garantindo direitos como o acesso à informação, explicação, contestação e revisão de decisões automatizadas.
c) Governança: O PL propõe mecanismos de governança como a avaliação de impacto algorítmico (AIA), similar ao relatório de impacto à proteção de dados pessoais (RIPD) da LGPD, visando minimizar riscos.
d) Fomento à inovação: O PL incentiva a inovação em IA, incluindo a criação de ambientes regulatórios experimentais (sandboxes), mas com ênfase na inovação responsável e na proteção de dados pessoais.
e) Autoridade competente: O PL prevê a designação de uma autoridade competente para zelar pela implementação e fiscalização da lei, com a ANPD defendendo o papel central da Autoridade na proteção de dados e governança da IA.
A ANPD – Autoridade Nacional de Proteção de Dados através da análise realizada entende que o PL “possui diversos pontos de interação com a LGPD”. (Análise preliminar do Projeto de Lei nº 2338/2023, que dispõe sobre o uso da Inteligência Artificial, 2023), a ANPD, continua a análise defendendo:
a) A compatibilização do PL com a LGPD, evitando sobreposição de competências;
b) O papel da ANPD como autoridade-chave na regulação e governança da IA no Brasil;
c) O foco na proteção de dados pessoais em sandboxes de IA, especialmente para sistemas de alto risco;
O PL 2338/2023 representa um avanço significativo na regulamentação da IA no Brasil, buscando equilibrar a inovação com a proteção de direitos fundamentais e a segurança jurídica. A ANPD desempenha um papel crucial nesse processo, defendendo a harmonização da regulação da IA com a LGPD e a proteção dos dados pessoais.
As Leis de IA no mundo são um marco importante na regulamentação da IA. Ela tem o potencial de moldar o futuro da IA na Europa e no mundo, e garantir que essa tecnologia seja usada para o bem.
A responsabilidade de mitigar esses riscos recai sobre os desenvolvedores de IA, os reguladores, as empresas que utilizam a tecnologia e a sociedade como um todo. É fundamental investir em pesquisa e desenvolvimento de tecnologias de IA que priorizem a privacidade, desenvolver mecanismos robustos de proteção de dados e promover uma cultura de responsabilidade e ética na utilização da IA.
Em resumo, a IA, embora seja uma tecnologia promissora, apresenta riscos significativos para a privacidade. Para aproveitar os benefícios da IA sem comprometer a privacidade, é essencial um esforço conjunto para desenvolver e implementar soluções que protejam a privacidade e garantam o uso responsável e ético da IA.
2.8 IMPLICAÇÕES DO GDPR E DA LGPD PARA A IA
O GDPR (Regulamento Geral de Proteção de Dados) e a LGPD (Lei Geral de Proteção de Dados) têm implicações significativas para o desenvolvimento e uso da Inteligência Artificial (IA) em diversos aspectos:
- a) Coleta e Uso de Dados Pessoais:
Transparência e Consentimento: A IA que coleta ou processa dados pessoais deve seguir princípios de transparência e consentimento. Isso significa que as pessoas precisam ser informadas sobre quais dados estão sendo coletados, como serão usados e com quem serão compartilhados, e devem ter a oportunidade de consentir ou não com a coleta e uso de seus dados.
Minimização de Dados: A IA deve coletar apenas a quantidade mínima de dados pessoais necessária para o propósito específico para o qual foi projetada. Dados desnecessários devem ser excluídos o mais rápido possível.
Finalidade Especificada: Os dados pessoais coletados por IA devem ser usados apenas para os propósitos específicos para os quais foram coletados e não podem ser usados para outros fins sem o consentimento explícito da pessoa.
Armazenamento Seguro: Os dados pessoais coletados por IA devem ser armazenados de forma segura para proteger contra acesso não autorizado, alteração ou perda.
- b) Tomada de Decisões Automatizada:
Não Discriminação: A IA não deve ser usada para tomar decisões automatizadas que discriminem indivíduos com base em características como raça, etnia, gênero, orientação sexual, religião ou outra característica protegida.
Direito à Explicação: As pessoas têm o direito de saber como as decisões automatizadas tomadas por IA os afetaram e quais dados foram usados para tomar essas decisões.
Direito à Revisão Humana: As pessoas têm o direito de solicitar que uma decisão automatizada tomada por IA seja revisada por um humano.
- c) Segurança e Proteção de Dados:
Medidas de Segurança Técnicas e Organizacionais: Os desenvolvedores e usuários de IA devem implementar medidas de segurança técnicas e organizacionais adequadas para proteger os dados pessoais contra acesso não autorizado, alteração ou perda.
Avaliações de Impacto à Proteção de Dados: Para sistemas de IA que apresentam alto risco à privacidade, deve-se realizar uma avaliação de impacto à proteção de dados para identificar e mitigar os riscos potenciais.
- d) Responsabilidade:
Desenvolvedores: Os desenvolvedores de IA são responsáveis por garantir que seus sistemas estejam em conformidade com os princípios do GDPR e da LGPD.
Usuários: Os usuários de IA também são responsáveis por garantir que seus sistemas estejam em conformidade com os princípios do GDPR e da LGPD.
O Papel da ANPD:
A ANPD (Autoridade Nacional de Proteção de Dados) é a autoridade responsável por supervisionar a aplicação da LGPD no Brasil. A ANPD tem um papel crucial na regulamentação da IA no Brasil, defendendo a harmonização da regulamentação da IA com a LGPD e a proteção dos dados pessoais. O GDPR e a LGPD impõem obrigações importantes para o desenvolvimento e uso da IA de forma ética e responsável. Ao seguir esses princípios, as empresas e organizações podem garantir que seus sistemas de IA estejam em conformidade com a lei e protejam a privacidade dos indivíduos.
2.9 DESAFIOS NA APLICAÇÃO DAS REGULAMENTAÇÕES DE PROTEÇÃO DE DADOS À IA
Para o GDPR (Regulamento Geral de Proteção de Dados) da União Europeia representa um marco importante na proteção de dados pessoais, mas a sua aplicação ao contexto da IA apresenta desafios específicos:
Definição de Dados Pessoais: A IA amplia a interpretação de “dados pessoais” ao possibilitar a reidentificação de dados aparentemente anônimos e inferir novas informações pessoais a partir de dados existentes. O GDPR, em sua definição, não aborda explicitamente essas nuances, criando incertezas e necessitando de clareza adicional para regulamentar esses cenários.
Restrições da IA em face de Princípios do GDPR: Os princípios do GDPR, como a limitação de finalidade, a minimização de dados e as restrições à tomada de decisão automatizada, podem parecer conflitar com as demandas de coleta e processamento de dados em larga escala inerentes à IA. A interpretação flexível desses princípios é crucial para conciliar a inovação tecnológica com a proteção de dados.
Consentimento e Repurposing: O consentimento, como base legal para o processamento de dados, pode ser inadequado no contexto da IA, principalmente para análises complexas de dados e a criação de perfis. O “repurposing” (reutilização de dados para fins distintos daqueles para os quais foram coletados), inclusive para pesquisa e fins estatísticos, precisa de diretrizes claras sobre compatibilidade e salvaguardas.
O Peso da Responsabilidade: O GDPR coloca a responsabilidade sobre os controladores de dados para garantir o cumprimento das normas. No entanto, a complexidade dos sistemas de IA, a falta de transparência e a dificuldade de controlar a tomada de decisões automatizada exigem um esforço adicional de auditoria, monitoramento e documentação para demonstrar a conformidade.
A LGPD, inspirada no Regulamento Geral de Proteção de Dados (GDPR) da União Europeia, representa um marco na proteção de dados pessoais no Brasil. A LGPD ainda é inexpressiva, dada a importância da regulamentação da IA, especialmente no que diz respeito ao direito à explicação e à responsabilização.
2.10 LEI GERAL DE PROTEÇÃO DE DADOS E A QUESTÃO DA EXPLICABILDADE
O direito à explicação, previsto no artigo 20 da LGPD, o chamado Transparência Algorítmica e Explicabilidade, assegura ao titular dos dados o direito de solicitar a revisão de decisões tomadas unicamente com base em tratamento automatizado de dados pessoais, desde que afetem seus interesses. O artigo demonstra que a aplicação desse direito a decisões complexas, que envolvem a interação de humanos com sistemas de IA.
A principal preocupação reside na eficiência e na amplitude do direito à explicação. A lei deixa a cargo da Autoridade Nacional de Proteção de Dados a decisão de realizar ou não auditorias, limitando sua atuação a casos de recusa do controlador em fornecer informações, alegando segredo comercial ou industrial. Essa limitação pode comprometer a proteção do titular dos dados, caso a recusa se baseie em outros fundamentos.
Além disso, a lei não prevê auditorias para investigar a veracidade da explicação fornecida pelo controlador ou a legitimidade e a legalidade da recusa em alterar a decisão automatizada. Essa ausência de diretrizes claras para a atuação da Autoridade Nacional pode comprometer a efetividade do direito à explicação.
2.11 LEI GERAL DE PROTEÇÃO DE DADOS E A QUESTÃO DO SEGREDO DE NEGÓCIOS
O segredo de negócios, por sua vez, é um instrumento jurídico que protege informações confidenciais utilizadas em atividades comerciais ou industriais, conferindo às empresas uma vantagem competitiva. No Brasil, a Lei de Propriedade Industrial (LPI), nº 9.279, de 1996, é responsável por regular a proteção de segredos comerciais e industriais, e a LGPD reconhece a importância de observar o segredo de negócios no tratamento de dados pessoais.
A relação entre a LGPD e o segredo de negócios torna-se ainda mais complexa com a utilização da IA. A IA impulsiona a coleta e o processamento massivo de dados, muitos deles de natureza pessoal. Os sistemas de IA utilizam algoritmos complexos para analisar esses dados e gerar insights e tomar decisões automatizadas, impactando a vida das pessoas de forma cada vez mais significativa.
A questão da transparência e da explicabilidade dos algoritmos é crucial neste contexto. Se os sistemas de IA tomarem decisões que afetem os direitos e os interesses dos indivíduos, é fundamental que eles possam compreender como essas decisões foram tomadas e quais dados foram utilizados para tanto. No entanto, a proteção de segredos comerciais pode impedir que essas informações sejam divulgadas, criando um dilema entre a transparência e a proteção da competitividade das empresas.
Como afirma Frank Pasquale, vivemos em uma “sociedade da caixa preta”, onde algoritmos, muitas vezes opacos, determinam não só o acesso a produtos e serviços, mas também moldam nossa identidade, pensamentos, direitos e perspectivas de futuro. Harari (2016) adverte para os riscos do “dataísmo”, uma verdadeira “religião dos dados” que pode levar à subjugação humana.
A questão da opacidade algorítmica ganhou destaque no meio jurídico, impulsionada por iniciativas como a perícia do algoritmo da Uber pela Justiça Trabalhista, com o objetivo de determinar o grau de controle da plataforma sobre seus motoristas e, consequentemente, definir a existência de vínculo empregatício. Apesar de duas decisões do Tribunal Superior do Trabalho (TST) terem suspendido provisoriamente esse tipo de prova, a necessidade de investigar a relação entre o algoritmo e o trabalho dos motoristas se mantém, especialmente considerando estudos que apontam para um controle algorítmico por parte da plataforma e o reconhecimento do vínculo de emprego em outros países.
A Lei Geral de Proteção de Dados (LGPD) reconhece a necessidade de transparência e accountability no tratamento de dados pessoais, mas também protege o segredo de negócios, criando um dilema crucial. O princípio da transparência, definido pela LGPD, é limitado pelo segredo comercial e industrial, configurando um “tradeoff” complexo. A LGPD menciona a necessidade de proteger o segredo comercial e industrial em diversas ocasiões, inclusive ao definir as competências da Autoridade Nacional de Proteção de Dados (ANPD).
Apesar das dificuldades jurídicas em relação à proteção do segredo de negócios, a busca por transparência algorítmica enfrenta um obstáculo técnico. A complexidade e ininteligibilidade dos algoritmos, especialmente aqueles que utilizam técnicas como machine learning e redes neurais, dificultam a compreensão de seus processos e decisões.
Surge, então, a necessidade de garantir a inteligibilidade dos algoritmos, ou seja, a clareza sobre seus aspectos principais e lógica de decisão, especialmente os critérios utilizados. Essa inteligibilidade permitiria a preservação do segredo de negócios, pois não revelaria o código integralmente, mas sim os elementos mais relevantes da decisão algorítmica, traduzidos da linguagem matemática para a linguagem natural.
A própria LGPD, ao mesmo tempo em que protege o segredo de negócios, reconhece a necessidade de explicabilidade de decisões algorítmicas que afetam terceiros. O direito à explicação e revisão de decisões totalmente automatizadas, previsto no artigo 20 da LGPD, reforça essa necessidade.
A LGPD prevê, inclusive, a possibilidade de auditorias externas independentes para atestar a idoneidade do sistema algorítmico, garantindo a transparência e combatendo a discriminação. A ANPD, por sua vez, possui competência para realizar auditorias nesse sentido.
Apesar da importância dessas ferramentas, a falta de implementação prática exige a busca por soluções alternativas para conciliar os direitos envolvidos, tanto de empresas quanto de terceiros afetados por decisões algorítmicas.
Para essa reflexão, é crucial analisar a natureza e os limites do segredo de negócios. A propriedade intelectual, incluindo a propriedade industrial e o direito autoral, não é absoluta, existindo discussões sobre a função social da propriedade e a necessidade de equilibrar os interesses do titular com os da sociedade.
Taylor Moore (2017) argumenta que, enquanto outros mecanismos de propriedade intelectual já equilibram os interesses do titular com os da sociedade, os segredos de negócios, apesar de serem considerados “propriedade intelectual”, não estão sujeitos a qualquer limite ou mecanismo de equilíbrio, sendo criados e mantidos pela vontade do titular. Isso reforça a necessidade de exigir transparência em situações que afetam diretamente terceiros.
É preciso considerar o segredo de empresa como um direito não absoluto, especialmente em situações em que interesses sociais relevantes podem ser prejudicados. Uma discussão atual é sobre a possibilidade de oposição do segredo de negócios ao regulador, que precisa compreender o que regula.
A Lei de Propriedade Industrial, no Brasil, prevê a revelação do segredo de negócios em casos excepcionais, no contexto de disputas judiciais, mediante o segredo de justiça.
O caso Compass, um sistema de inteligência artificial utilizado para auxiliar na dosimetria da pena em Wisconsin, ilustra a importância da transparência algorítmica. A falta de inteligibilidade e transparência da decisão, justificada pela empresa fornecedora do sistema sob a alegação de segredo de negócios, gerou grande mobilização social e jurídica, mostrando que o segredo de negócios não poderia prevalecer em casos que envolvem direitos fundamentais.
Frank Pasquale (2015), em seu artigo “Algoritmos secretos ameaçam a rule of law”, alerta para os riscos de decisões algorítmicas opacas, que impedem a defesa do réu e minam o sistema jurídico. A falta de transparência impede a fundamentação aberta ao público e o devido processo legal.
A discussão sobre a transparência algorítmica se intensificou após o caso Compas, com diversos trabalhos defendendo a necessidade de abrir mão do segredo de negócios em casos de condenações criminais.
Decisões algorítmicas enviesadas ou discriminatórias, bem como decisões que impactam relações assimétricas, como as relações de trabalho, exigem atenção especial. O caso de Daniel Santos e outros professores de Houston, demitidos por um sistema de avaliação algorítmico opaco, demonstra os impactos negativos da opacidade algorítmica na vida de trabalhadores. O sindicato dos professores entrou com ação contra o Houston Independent School District, alegando violação ao devido processo legal. O caso resultou em acordo, mas expôs a necessidade de transparência e accountability em sistemas de inteligência artificial, especialmente na área trabalhista.
No caso da Uber, a opacidade do algoritmo gera controvérsias, não apenas no Brasil, mas também no Reino Unido, onde motoristas entraram com ação judicial para ter acesso a seus dados pessoais e à accountability algorítmica, baseados no GDPR.
É essencial refletir sobre as consequências da recusa da Uber em abrir seu algoritmo, considerando a relação entre o segredo de negócios e a prova judicial. O direito de manter o segredo de negócios não deve ser confundido com a impossibilidade de provar uma relação de emprego que depende do algoritmo.
O Supremo Tribunal Federal, em um caso de investigação de paternidade, reconheceu o direito do réu de não realizar o teste de DNA, mas também entendeu que a recusa em produzir a prova deveria ter impactos na distribuição dos ônus da prova, criando uma presunção relativa de paternidade.
A questão da recusa de produzir provas determinantes em processos judiciais, mesmo sob alegação de exercício regular de direito, exige reflexão sobre a inversão dos ônus da prova, como previsto no Código de Processo Civil.
Se os tribunais trabalhistas considerarem a impossibilidade de abrir o código da Uber, mesmo em processo judicial sob sigilo, precisarão analisar os impactos da recusa da plataforma sobre a atribuição dos ônus da prova e a possibilidade de presunção relativa de vínculo empregatício.
O pior cenário seria permitir que a plataforma se beneficiasse do segredo de negócios de forma ampla e absoluta, inclusive para fins probatórios. Isso chancelaria, indiretamente, fraudes e burlas à legislação trabalhista.
A discussão sobre a opacidade algorítmica nos leva a questionar se os algoritmos, vistos como “armas” em diversos contextos, podem ser utilizados como “escudos”, especialmente se o segredo de negócios for considerado uma defesa absoluta em processos judiciais, sem qualquer repercussão sobre os ônus da prova.
3. CONCLUSÃO
A inteligência artificial (IA) avança a passos largos, prometendo revolucionar diversos setores da sociedade. Seus benefícios são inegáveis, desde a otimização de processos e a criação de novas soluções até a promessa de melhorar a qualidade de vida humana. No entanto, o desenvolvimento e a aplicação da IA trazem consigo desafios éticos, legais e sociais complexos, exigindo uma abordagem cuidadosa para evitar consequências negativas.
Uma das principais preocupações reside nos vieses, discriminação e falta de transparência em algoritmos, sobretudo em sistemas de machine learning. A utilização de IA em áreas sensíveis, como saúde, justiça e segurança pública, exige que se garantam a equidade, a justiça e a proteção dos direitos humanos. A falta de transparência, por exemplo, impede o controle e a possibilidade de questionar resultados potencialmente prejudiciais, tornando crucial a busca por mecanismos que garantam a transparência sem comprometer a inovação e a competitividade.
Outro ponto crucial é a questão da privacidade. O acesso a grandes volumes de dados, necessários para o treinamento de modelos de IA, cria uma tensão entre a inovação tecnológica e a proteção da vida privada dos indivíduos. A busca por soluções que garantam a segurança dos dados e o controle sobre seu uso é essencial para construir uma sociedade digital justa e ética.
A implementação de leis e diretrizes éticas para a IA é essencial para orientar o desenvolvimento e o uso responsável dessa tecnologia. A construção de um diálogo aberto e colaborativo entre pesquisadores, desenvolvedores, governos e sociedade civil é fundamental para estabelecer padrões éticos e legislações adequadas que promovam o benefício da IA para toda a humanidade.
A IA tem o potencial para transformar o mundo de forma positiva, mas é crucial que seu desenvolvimento e aplicação sejam guiados por princípios éticos e valores humanos. Somente com um esforço conjunto e uma reflexão profunda sobre as implicações da IA será possível construir um futuro tecnologicamente avançado e, ao mesmo tempo, justo e equitativo para todos.
REFERÊNCIAS
BERTINO, E.; KUNDU, S.; SURA, Z. Transparency in Artificial Intelligence and Autonomous Systems: Designing for Ethical Resilience. IEEE Security & Privacy, v. 17, n. 1, p. 34-43, 2019.
BRASIL. Senado Federal. Projeto de Lei nº 2.789, de 2023. Dispõe sobre o uso de Inteligência Artificial. Disponível em: https://www25.senado.leg.br/web/atividade/materias/-/materia/157233. Acesso em: 18 abr. 2024.
CHALLEN, R. et al. Artificial intelligence, bias and clinical safety. BMJ Quality & Safety, v. 28, n. 3, p. 231-237, 2019.
CHEN, Z. Privacy Protection Technology in the Age of A.I. In: IOP Conference Series: Materials Science and Engineering, v. 750, p. 012103, 2020.
COOLEY, R.; MOBASHER, B.; SRIVASTAVA, J. Mineração da Web: descoberta de informações e padrões na World Wide Web. In: Proceedings da 9ª Conferência Internacional IEEE sobre Ferramentas com Inteligência Artificial, Newport Beach, CA, EUA, 1997.
HARARI, Yuval Noah. Homo Deus: Uma breve história do amanhã. São Paulo: Companhia das Letras, 2016.
JOBIN, A. et al. The global landscape of AI ethics guidelines. Nature Machine Intelligence, v. 1, n. 9, p. 389-399, 2019.
KRISHNAPRIYA, P. V.; POOJA, R. N.; SRIDEVI, V. A Review on Bias in Facial Recognition Systems. International Journal of Advanced Science and Technology, v. 29, n. 6, p. 4585-4594, 2020.
LICHTENTHALER, Ulrich. An Intelligence-Based View of Firm Performance: Profiting from Artificial Intelligence. Journal of Innovation Management, v. 7, n. 1, p. 7-20, 2019. Disponível em: https://hdl.handle.net/10216/119830. DOI: https://doi.org/10.24840/2183-0606_007.001_0002. Acesso em: 18 abr. 2024.
MOORE, Taylor. Trade Secrets and Algorithms as Barriers to Social Justice. CDT Free Expression Fellow, 2017. Disponível em: https://cdt.org/wp-content/uploads/2017/08/2017-07-31-Trade-Secret-Algorithms-as-Barriers-to-Social-Justice.pdf. Acesso em: 10 mar. 2024.
MURDOCH, T. B. Data Breaches: Definition, Notification Requirements, and Recent Cases. In: Encyclopedia of Cyber Risk Management, 2021.
PALAIOGEORGOU, V. E. et al. Data Protection and Privacy Issues in Artificial Intelligence-Driven Smart Surveillance. In: Proceedings of the 54th Hawaii International Conference on System Sciences, 2021.
PASQUALE, Frank. The black box society: The secret algorithms that control money and information. Cambridge: Harvard University Press, 2015.
RAVI, I.; IGNATIUS, J. Privacy in the AI Era: Navigating challenges and safeguarding data in the age of innovation. Information Systems Security, 2023.
SCHMIDT, S.; BIESSMANN, F.; TEUBNER, T. Bias and Fairness in Machine Learning. In: International Conference on Database and Expert Systems Applications, 2020.
TAYLOR, Petroc. Amount of data created, consumed, and stored 2010-2020, with forecasts to 2025. Statista, 16 nov. 2023. Disponível em: https://www.statista.com/statistics/871513/worldwide-data-created/. Acesso em: 19 set. 2023.
TÓTH, M. et al. Legal and Ethical Aspects of Artificial Intelligence Systems. In: Proceedings of the International Conference on Information Systems Architecture and Technology, 2022.
NOTA
O autor utilizou a l CHATGPT, GPT-4-Turbo para correção da gramática dos textos e sugestão de alteração de algumas expressões. No entanto, todas as buscas pelos conteúdos, classificação da qualidade dos artigos e referências foram realizadas de maneira autoral.
[1] Mestrado em Teologia, LLM – Master of Laws (com título duplo para Brasil e Europa), Pós-graduação Lato Sensu – Especialização em Direito Digital, Bacharel em Teologia, Bacharel em Engenharia de Produção, Tecnologo em Análise de Sistemas. ORCID: 0009-0007-0213-3447.
Material recebido: 27 de setembro de 2024.
Material aprovado pelos pares: 28 de outubro de 2024.
Material editado aprovado pelos autores: 24 de dezembro de 2024.